尾递归会被优化成循环,不会导致爆栈
查找
静态查找: 集合记录固定,没有插入删除操作
动态查找: 集合记录不固定,存在插入删除操作
哨兵
在数组的边界上设置一个值,使得循环条件到哨兵时必然导致循环退出,以减少循环条件判断。[[二分搜索#端点处理]]
顺序查找
时间复杂度
二分查找
要求
- 可查找到元素:
 在上图的序列中查找
在上图的序列中查找
- 首先计算出
- 因为
,将 ,此时 (下取整) - 因为
,更新 的值,计算 - 此时
,搜索结束
- 不可查找到元素:

在上图序列中找 43
- 此时
,搜索结束,找不到元素
STL 二分
默认升序序列,降序需要重载运算符。
binary_serach(arr[],arr[]+size,key);//是否找到key
lower_bound(arr[],arr[]+size,key);//返回第一个大于等于key的地址
upper_bound(arr[],arr[]+size,key);//返回第一个大于key的地址
distance(iterator a,itreator b);通过这些函数配合,可以求出区间内符合条件的数的个数。 注意事项
- Distance 函数有前后之分
- 当 insert 容器后之前的迭代器会失效
- 二分前提是一个升序(非降序)对象
二分查找判定树
 树的深度决定了最坏情况下的查找次数
树的深度决定了最坏情况下的查找次数
- 判定树上每个节点需要的查找次数等于该节点所在的层数
个节点的判定树深度为 - 平均查找次数 ASL =
树
定义
- 树是
个结点构成的有限集合。 ,称为空树 - 根节点用
表示(root) - 其余节点可分为
个互不相交的有限集 ,其中每个集合都可看成原来树的子树 - 不同子树节点之间不可相连,每个结点只有一个父节点
个结点的树有 条边
术语
- 结点的子树个数称之为度
- 树的所有节点中最大的度数称之为树的度
- 度为 0 的节点为叶节点 ^ae90eb
- 有子树的节点为子树的父节点
- 若 A 节点是 B 节点的父节点,则 B 是 A 的子节点
- 具有同一父节点的为兄弟节点
- 从
到 的边的个数称之为路径长度 - 从树根到某一节点上的所有节点称之为这个节点的祖先节点
- 某一节点的子树中的所有节点是这个节点的子孙节点
- 根节点为第一层,其他任意节点是父节点的层数加 1
- 树中所有节点的最大层次是这棵树的深度
二叉树
二叉树:儿子-兄弟表示法 表示下一层的儿子和本层的兄弟,如果没有则用表示为 N; 表示的一课树:
表示下一层的儿子和本层的兄弟,如果没有则用表示为 N; 表示的一课树: 
定义
二叉树是一个有穷的节点集合。 若不为空,由左子树
特殊二叉树
斜二叉树、完美二叉树、完全二叉树、 
性质
- 第
层的最大节点数为 ,由等比求和推导,完美二叉树符合
- [[树#^ae90eb]] 满足
 推导:
推导:
抽象数据类型定义、遍历

存储
数组存储

- 非根节点的父节点为
- 第 i 层的父节点的下一层为
和 如果是一般二叉树,则可以补成完全二叉树再通过数组存储,但显然会造成空间浪费。
链表存储

遍历
核心问题是将二维结构线性化。
先序遍历
根节点>左子树>右子树 从根节点开始分别对左右子树做先序遍历,对每个子树都是如此。 
中序遍历
左子树>根节点>右子树 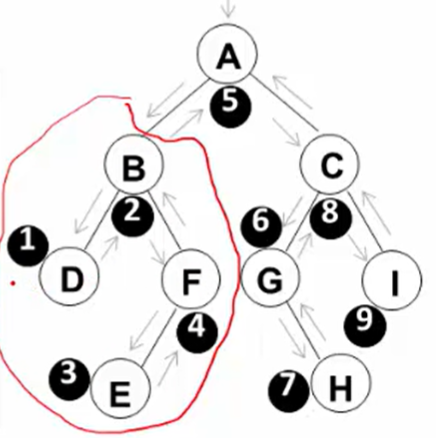
后序遍历
左子树>右子树>根节点 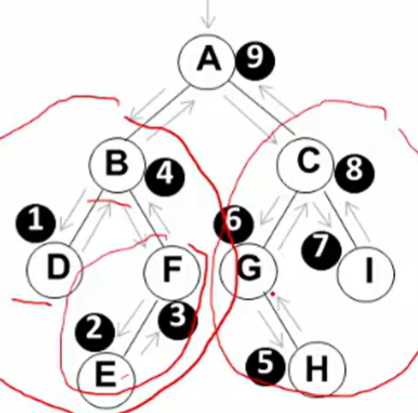 容易发现,所谓先后就是值访问根节点的次序先后,遍历顺序相同,只不过是访问各节点数据的时机不同。
容易发现,所谓先后就是值访问根节点的次序先后,遍历顺序相同,只不过是访问各节点数据的时机不同。
中序非递归遍历
这是针对完全二叉树的, 最后的结束条件是没有右子树且堆栈为空。 
无论是堆栈和队列都是用来保存遍历过程中暂时不访问的节点。
层序遍历
一层一层向下访问即可。 
[[队列]] [[2023.12.29#广度优先搜索]]
二元运算表达式树
中缀表达式会会受到运算符优先级影响,需要加括号消除。 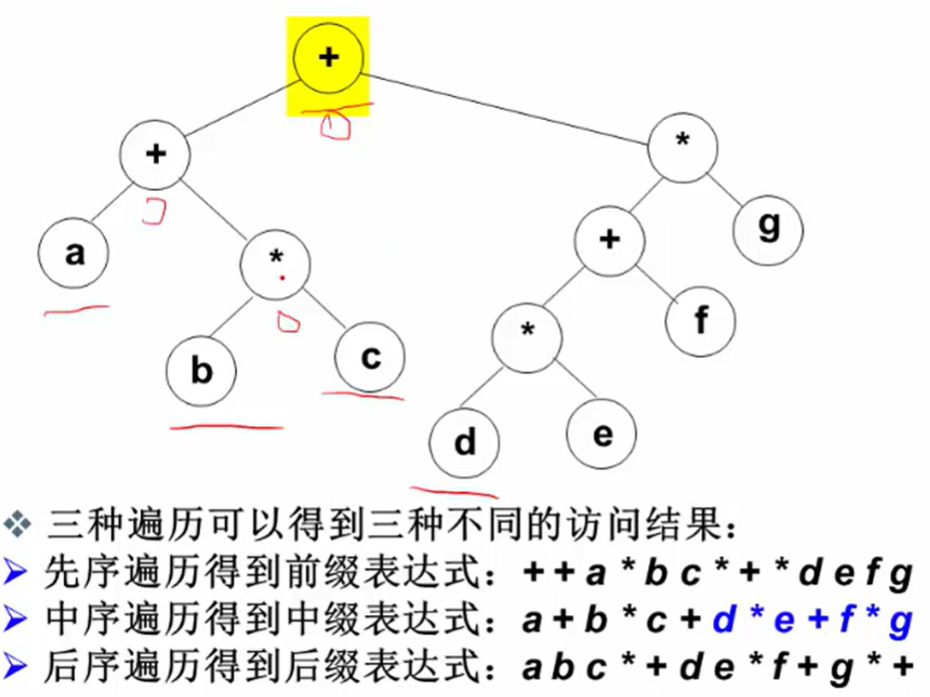
[[堆栈#表达式求值]]
先序+中序确定二叉树
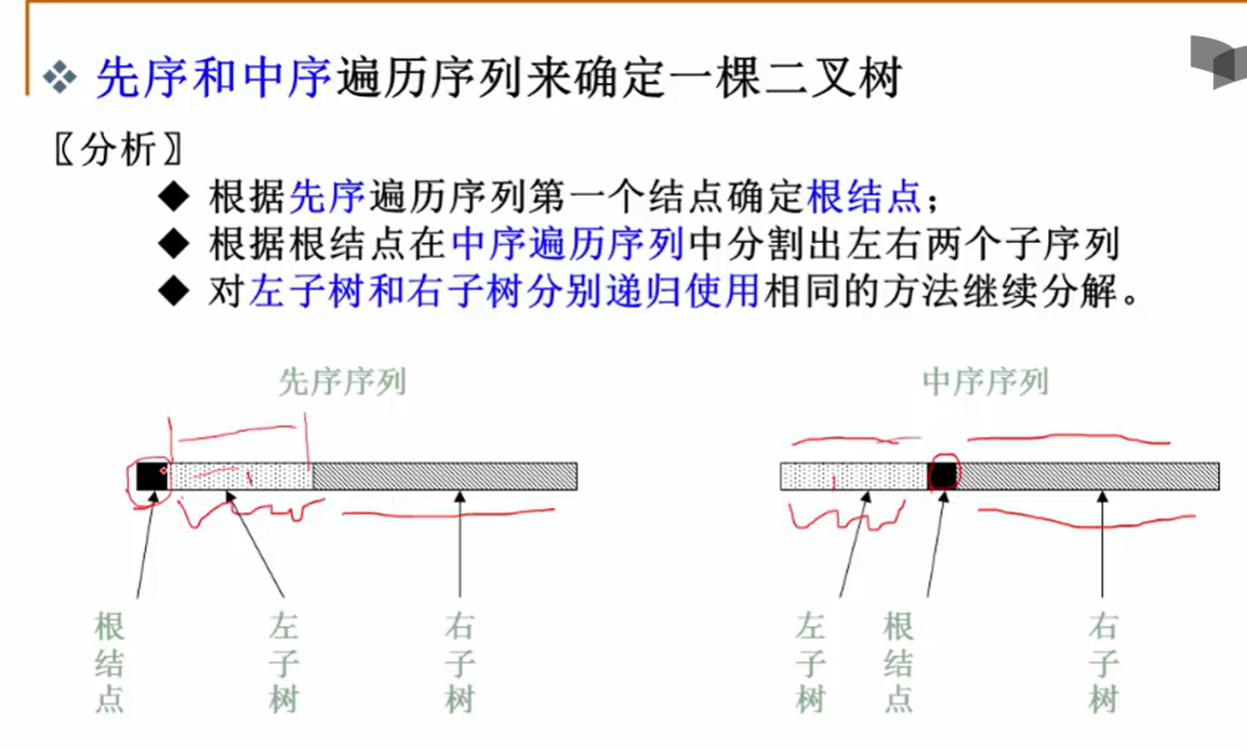
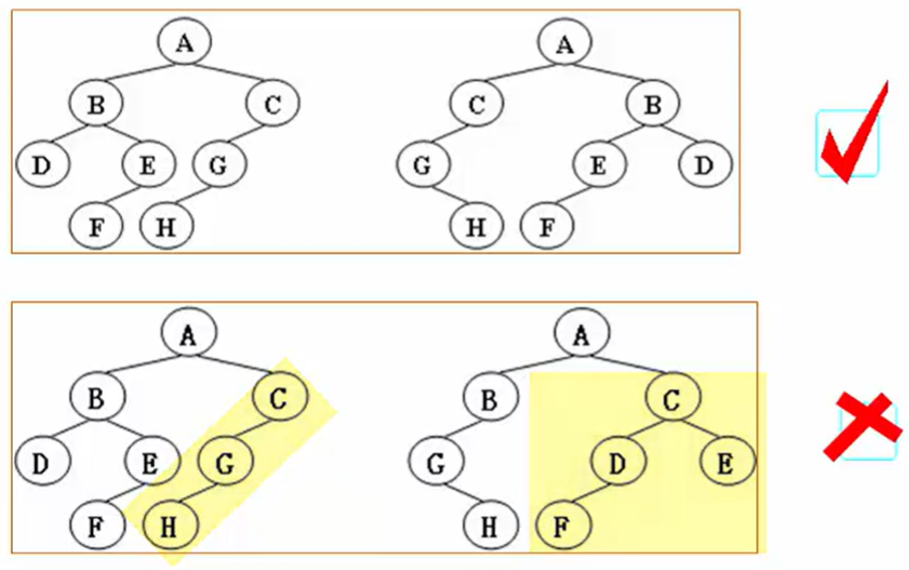
同构二叉树判断
P135 4-2.1
- 静态链表 [[链表模拟#牛客周赛 Round 31 D]] 建树 从 0 开始编号,
left和right是对应节点在数组中的位置。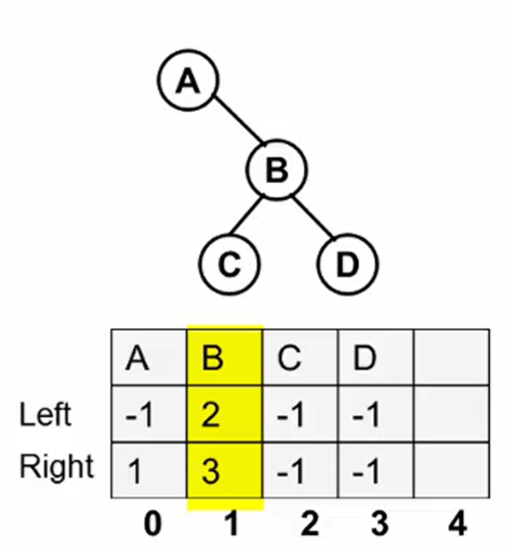
 那么如何找到根节点呢?只需要找到数组中唯一没有被记录的节点 1,因为记的都是下一级节点,根节点自然没有父节点来记录它。
那么如何找到根节点呢?只需要找到数组中唯一没有被记录的节点 1,因为记的都是下一级节点,根节点自然没有父节点来记录它。 - 程序实现
- 读入二叉树,存进数组,并确定根节点
- 使用前序遍历判定同构
- 左右空则同构
- 左右有一侧空则不同构
- 根节点不同则不同构
- 如果均没有左子树,就要递归判断右子树是否同构
- 左右非空,且左节点相同,则判定两棵树的左节点元素是否相同,判定左右是否相等
- 左右非空,且左节点不相同,则判断左右是否同构


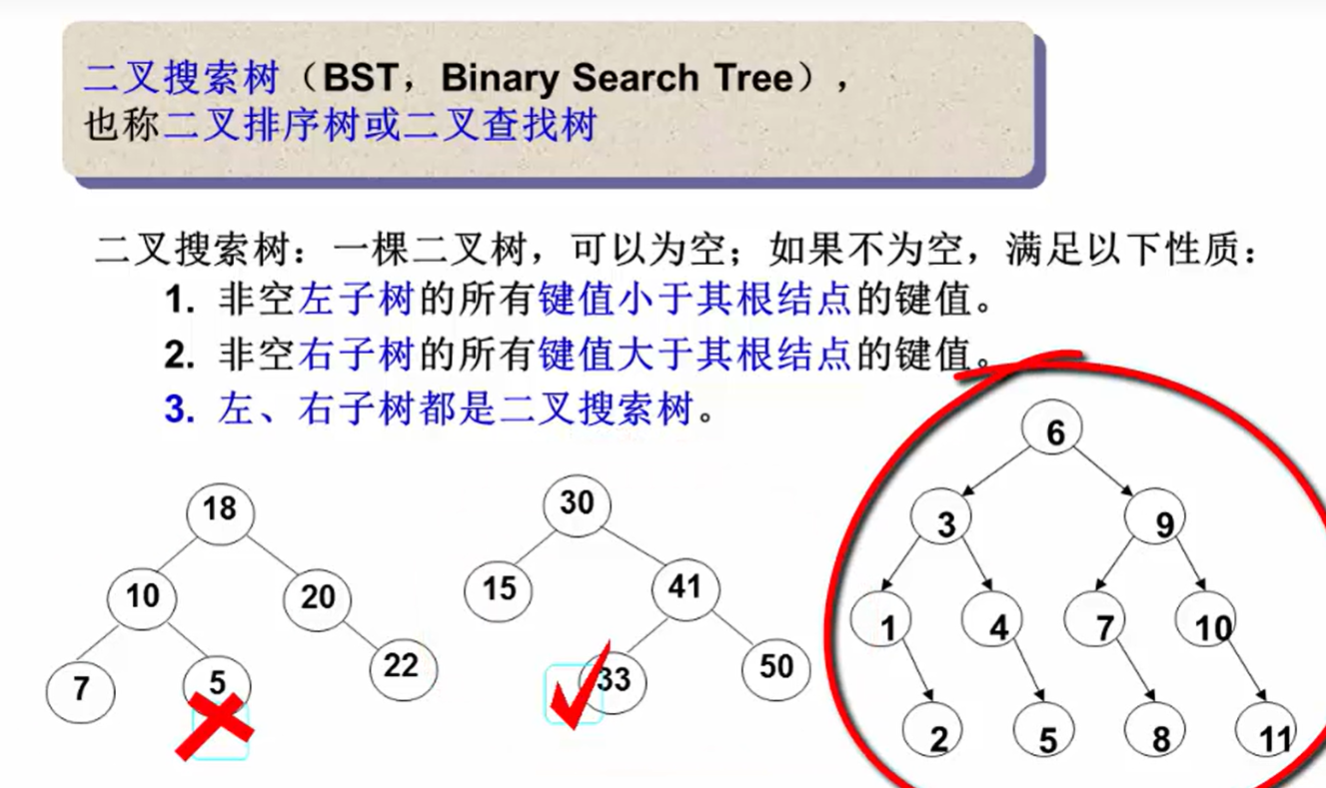
二叉搜索树
AVL 树
单旋调整
左右单旋取决于破坏 AVL 平衡的节点所在的位置是被破坏的左子树还是右子树。 破坏者位于左子树的左侧或者是右子树的右侧。 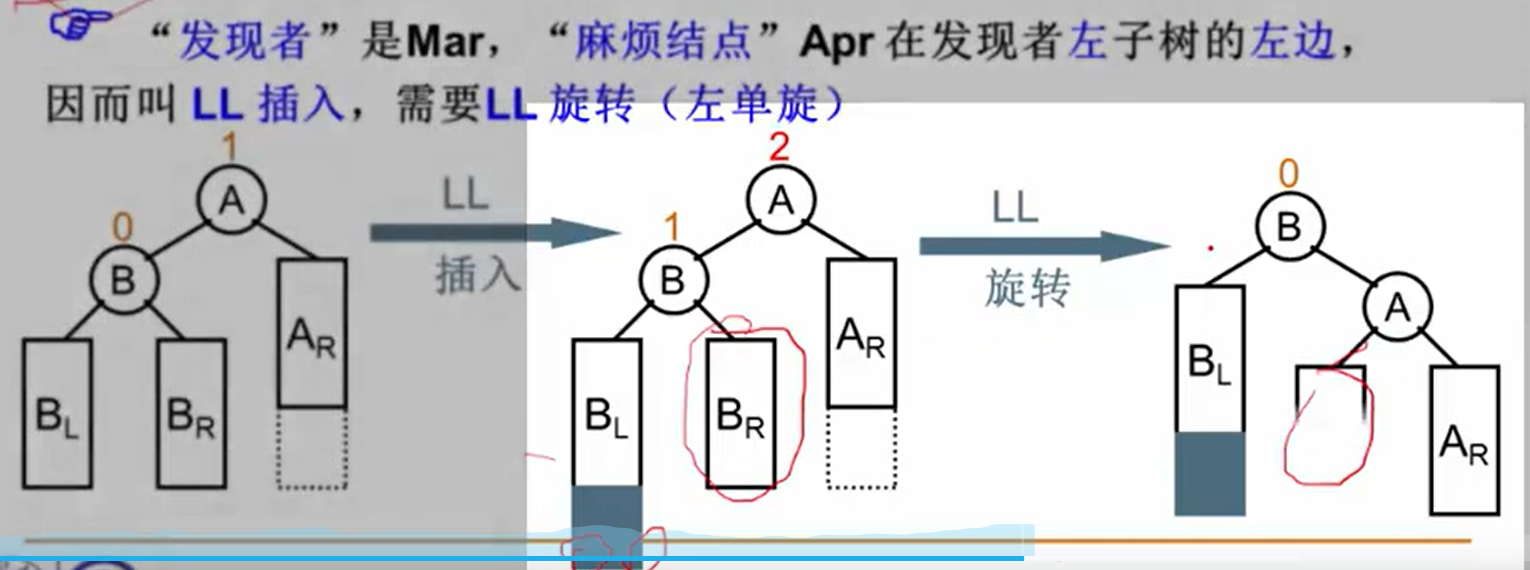
双旋调整
哈夫曼树
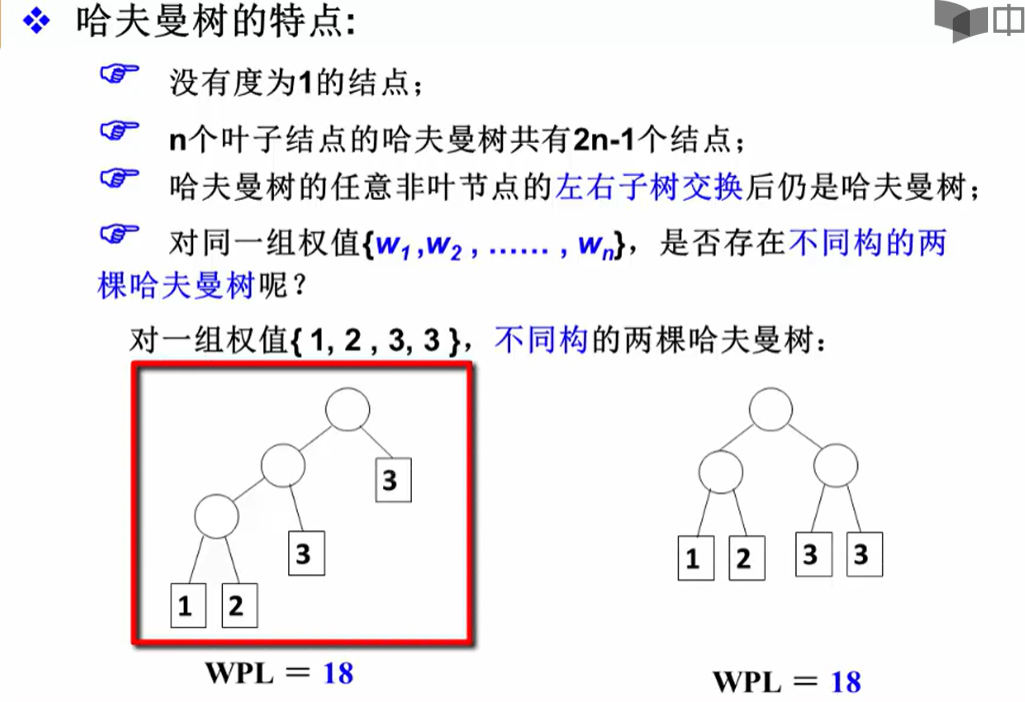 由哈夫曼树的过构造过程可知,哈夫曼树不存在度为 1 的接非叶子结点。
由哈夫曼树的过构造过程可知,哈夫曼树不存在度为 1 的接非叶子结点。 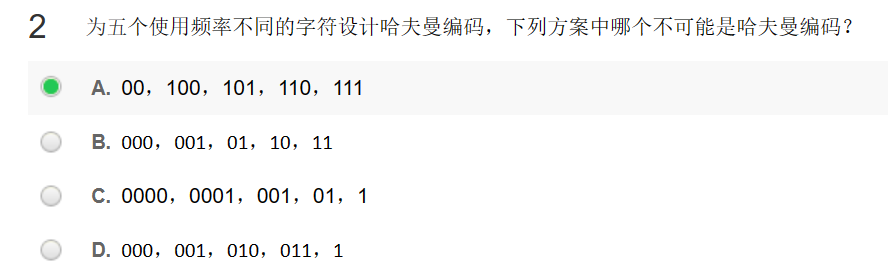

集合
结构数组表示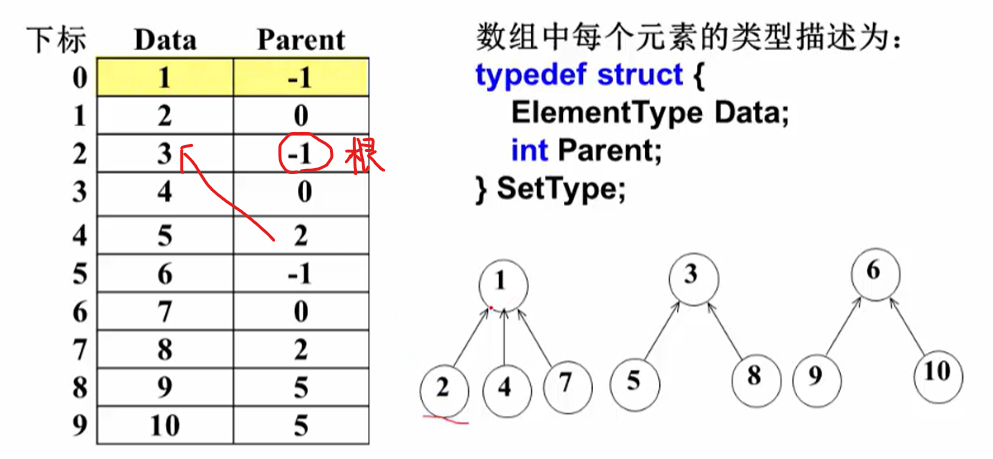
按秩归并
先讨论未经路径压缩后的集合树。 最坏情况或许是一个艮节点正好合并了两个相等大小的集合?这时候树高
路径压缩
 一次合并通常需要两次查找,所以
一次合并通常需要两次查找,所以
[[堆]]
建树
- 先序+中序建树
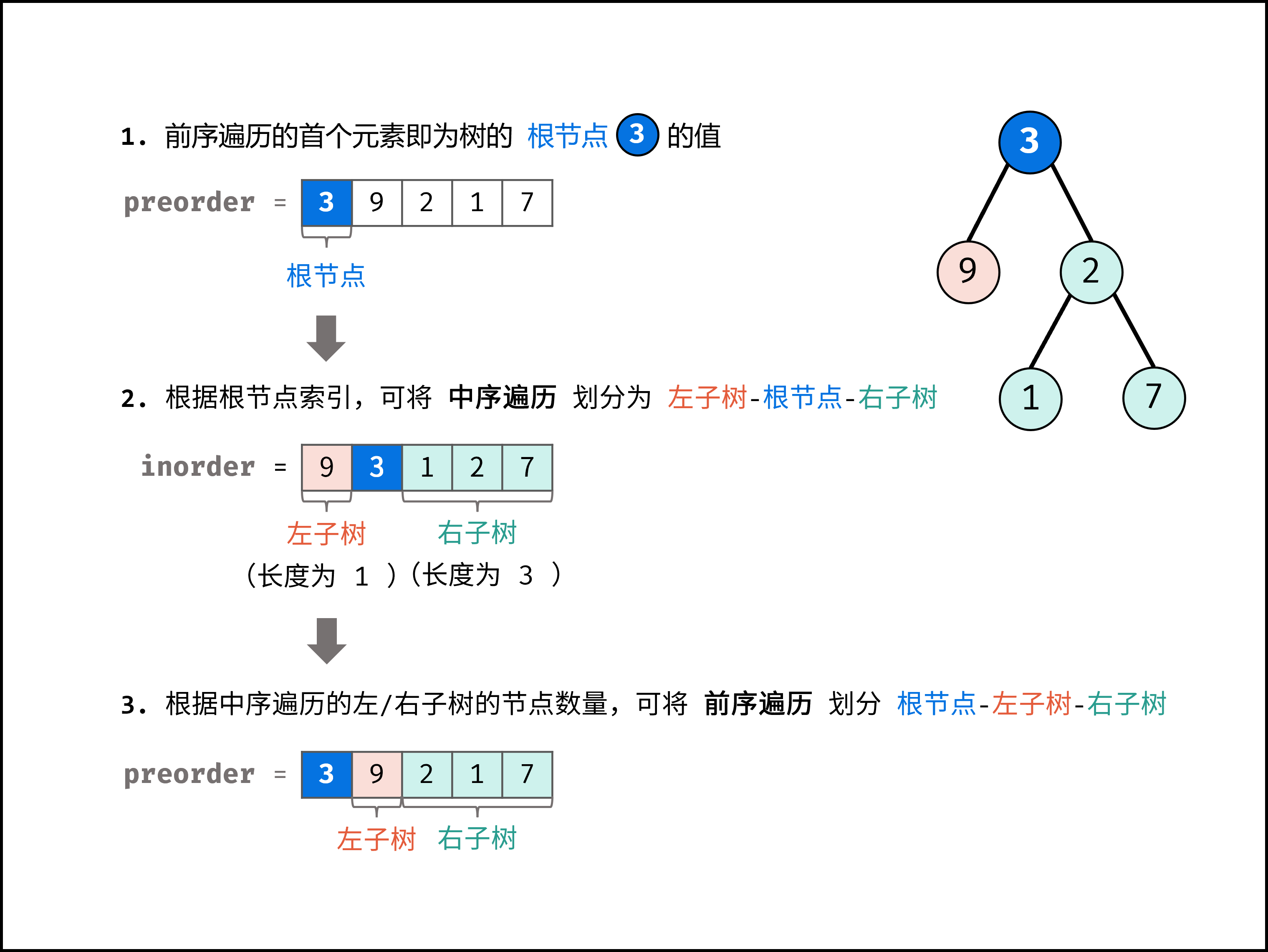 注意中序遍历只起到辅助作用,最终划分的还是前序遍历的结果。 根据先序遍历结果确定根节点,然后由此给中序分段,再用左右子树进行递归建树。
注意中序遍历只起到辅助作用,最终划分的还是前序遍历的结果。 根据先序遍历结果确定根节点,然后由此给中序分段,再用左右子树进行递归建树。
class Solution {
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
this->preorder = preorder;
for(int i = 0;i < inorder.size();++i){
dic[inorder[i]] = i;//按照下标建立一个哈希表索引
}
return recur(0,0,inorder.size()-1);
}
private:
vector<int> preorder;
unordered_map<int,int> dic;
TreeNode* recur(int root,int left,int right){//left和right是中序遍历的边界
if(left > right) return nullptr;
TreeNode* node = new TreeNode(preorder[root]);//pre的第一个节点就是当前的根节点
int index = dic[preorder[root]];
node->left = recur(root+1,left,index-1);
node->right = recur(index-left+1+root,index+1,right);//就是加上一个左子树的长度
return node;
}
};